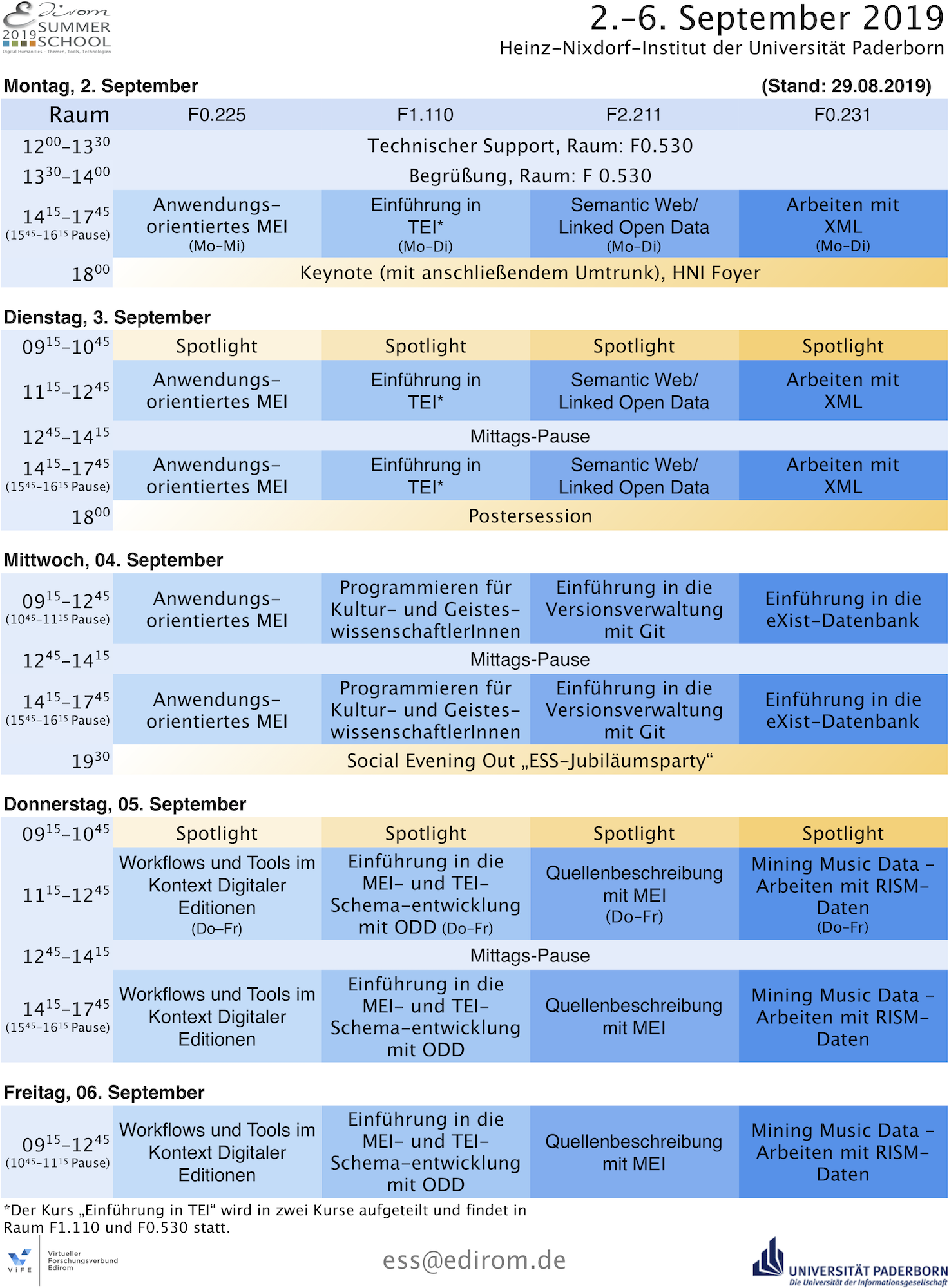
Kursprogramm ESS 2019
Die Edirom Summer School 2019 findet in diesem Jahr vom 2. bis 6. September statt. Zur bequemen An- und Abreise beginnt die ESS Montagmittag und endet Freitagmittag, 12:45 Uhr. Die Kurse beginnen «c.t.», sodass das Heinz-Nixdorf-Institut mit dem Bus aus der Stadt pünktlich erreicht werden kann.
Anwendungsorientiertes MEI
Johannes Kepper,Agnes Seipelt
Universität Paderborn
Musikwissenschaftliches Seminar Detmold/Paderborn
Beethovens Werkstatt
Mo, 2. September, 14:15 Uhr bis Mi, 4. September, 17:45 Uhr
F2.221
Statt einer abstrakten Einführung in MEI sollen gezielt häufige Anwendungsfälle diskutiert und geeignete Workflows für typische Aufgaben wie die Transkription und Codierung (musikalischer) Quellen vermittelt werden. Erste Erfahrungen im Umgang mit MEI oder anderen XML-basierten Formaten sind wünschenswert; Teilnehmer*innen ohne Vorkenntnisse in MEI oder anderen XML-basierten Formaten sollten im Vorfeld die MEI Tutorials unter https://music-encoding.org/resources/tutorials.html absolvieren. Am Ende des Kurses sollen sie in der Lage sein, eigenständig konsistente MEI-Daten in hoher Qualität zu erstellen und zentrale Modellierungsfragen anwendungsbezogen entscheiden können.
- Kurssprache
- deutsch
- Voraussetzungen/Vorkenntnisse
- XML
- Software
- oXygen XML Editor
- Zielgruppe
- Einsteiger
- Kosten
- 50,- Euro
Arbeiten mit XML
Benjamin W. Bohl
Goethe Universität Frankfurt am Main
Institut für Musikwissenschaft
Bernd Alois Zimmermann-Gesamtausgabe
Mo, 2. September, 14:15 Uhr bis Di, 3. September, 17:45 Uhr
F0.231
Mit der zunehmenden Digitalisierung der Geisteswissenschaften haben immer mehr XML-basierte Formate Fuß gefasst, so etwa TEI (Text Encoding Initiative) oder MEI (Music Encoding Initiative) in den Bereichen der Text- bzw. Musikedition, XML-Serialisierungen von Ontologiekozepten wie etwa XTM (XML Topic Maps) zur Codierung von Beziehungsstrukturen oder die Keyhole Markup Language (KML) zur Beschreibung von Geodaten.
Diese Formate werden flankiert von technischen Formaten, Abfrage- und Programmiersprachen, die sowohl im Erstellungsprozess der Daten Hilfe leisten, als auch bei deren Nutzung und Weiterverarbeitung. Dieser Kurs soll anhand unterschiedlicher Beispieldatensätze aus den oben genannten Formaten einen Überblick geben über:
- Erweiterte Suchmöglichkeiten (reguläre Ausdrücke, XPath)
- Methoden zur Inhaltlichen Kontrolle mit Schemasprachen (XSD, relaxNG, Schematron)
- Möglichkeiten der Weiterverarbeitung und Abfrage (XSLT, XSL-FO, XQuery)
Die Kursteilnehmer sind explizit dazu aufgerufen, konkrete Fragestellungen aus dem Bereich der Kursinhalte vorab an den Dozenten zu senden. Bitte mit Beispieldateien, die im Kurs benutzt werden können.
- Kurssprache
- deutsch
- Voraussetzungen/Vorkenntnisse
-
- Sicherer Umgang mit XML, XML Namespaces,
- Sicherer Umgang mit mindestens einem der eingangs genannten XML-Formate,
- Sicherer Umgang mit oXygen XML Editor
- Grundlagen im Bereich der Kursinhalte erwünscht
- Software
- oXygen XML Editor, aktueller Internet-Browser
- Zielgruppe
- Einsteiger
- Kosten
- 30,- Euro
Einführung in TEI
Kristin Herold, Joachim Veit (Kurs 1)
Universität Paderborn
Musikwissenschaftliches Seminar Detmold/Paderborn
Carl-Maria-von-Weber-Gesamtausgabe
Beethovens-Werkstatt
Peter Stadler (Kurs 2)
Universität
Paderborn
Musikwissenschaftliches Seminar Detmold/Paderborn
Mo, 2. September, 14:15 Uhr bis Di, 3. September, 17:45 Uhr
Kurs 1: F1.110
Kurs 2: F0.530
Der Kurs führt in die Grundlagen der Textauszeichnung nach den Richtlinien der Text Encoding Initiative (TEI) ein. TEI wurde als XML-basierte Auszeichnungssprache speziell für die Zwecke der Geisteswissenschaften konzipiert und ist inzwischen als Standard für die wissenschaftliche Textkodierung so etabliert, dass neue Texteditions-Projekte ohne die Anwendung dieses Standards kaum noch denkbar (und förderwürdig) sind.
Nach einer knappen allgemeinen Einführung in XML werden sich die Teilnehmer*innen anhand von kleinen Übungen in die Praxis der Textauszeichnung mit TEI einarbeiten und einen Überblick über die Bedeutung und die verschiedenen Module dieser Sprache erhalten. Vordergründiges Ziel des Kurses ist es, die Teilnehmer*innen zu einem selbstständigen Umgang mit den TEI-Guidelines anzuleiten und damit für eine spezifische Vertiefung im Rahmen ihrer Projekte zu rüsten.
Update (8. August 2019)
Die Anmeldung für diesen Kurs ist wieder freigeschaltet und es wird ein zweiter Kurs zur selben Zeit angeboten!
- Kurssprache
- deutsch
- Voraussetzungen/Vorkenntnisse
- keine
- Software
- XML-Editor (z.B. oXygen), Internetbrowser
- Zielgruppe
- Einsteiger
- Kosten
- 30,- Euro
Einführung in die MEI- und TEI-Schemaentwicklung mit ODD
Peter Stadler
Universität Paderborn
Musikwissenschaftliches Seminar Detmold/Paderborn
Do, 5. September, 11:15 Uhr bis Fr., 6. September, 12:45 Uhr
F1.110
ODD („One Document Does it all“) ist eine von der TEI entwickelte Meta-Sprache, mit der dem „Literate Programming“-Ansatz folgend einerseits die formale Beschreibung eines TEI- oder MEI-Schemas erstellt werden kann als auch dessen menschenlesbare Beschreibung in Prosaform. Dabei ist ein ODD-Dokument selbst eine reguläre TEI-Datei (lediglich erweitert durch das tagdocs-Modul) so dass sich mit etwas Erfahrung in TEI relativ schnell auch spezielle Schemata für das eigene Projekt entwickeln und anpassen lassen.
In diesem Kurs wird zunächst das Konzept von ODD sowie die zugrundeliegenden Modul- und Klassensysteme von MEI und TEI vorgestellt und dann mithilfe des Roma-Webeditors ein erstes eigenes Schema erstellt. Ein weiterer Teil wird das Verfassen der Schema-Dokumentation (=elektronische Editionsrichtlinien) behandeln, wofür das ODD-Dokument „von Hand“ weiterentwickelt wird.
- Kurssprache
- Deutsch
- Voraussetzungen/Vorkenntnisse
- Software
- Zielgruppe
- Kosten
- 20,– Euro
Einführung in die Versionsverwaltung mit Git
Volker Spaarmann
Universität
Paderborn
Institut für Medienwissenschaften
Mi, 4. September, 09:15 Uhr bis 17:45 Uhr
F0.225
Die Verwaltung von Forschungsdaten mit einem Versionskontrollsystem wie zum Beispiel git gewinnt mehr und mehr an Bedeutung. Sie erlaubt nicht nur das koordinierte, kollaborative Arbeiten im Team, auch für den Einzelnen bietet z.B. die Bearbeitungshistorie einen deutlichen Vorteil. Nicht zuletzt können Forschungsergebnisse auf einer Online-Plattform wie GitHub nachnutzenden Wissenschaftlern zur Verfügung oder der Öffentlichkeit zugänglich gemacht werden.
Im Rahmen des Kurses werden anhand eines kleinen Praxisbeispiels die Grundfunktionalitäten von git erklärt und eigenständig nachempfunden. Sie lernen wie sie ein Repository anlegen, das Repository nach dem GitFlow-Modell strukturieren, Modifikationen an den Daten einspielen und Konflikte lösen können.
- Kurssprache
- Deutsch
- Voraussetzungen/Vorkenntnisse
- Keine
- Software
- Git, GitHub Desktop, GitHub-Account
- Zielgruppe
- Einsteiger und Fortgeschrittene
- Kosten
- 20,– Euro
Einführung in die eXist-Datenbank
Marcel Schaeben
Cologne Center for eHumanities
Mi, 4. September, 09:15 Uhr bis 17:45 Uhr
F0.231
eXist-db ist eine in den Digitalen Geisteswissenschaften recht weit verbreitete XML-Datenbank, die sich über die Jahre hin zu einem Framework zur Erstellung XML-basierter Webanwendungen entwickelt hat. Für GeisteswissenschaftlerInnen mit grundlegenden Kenntnissen der X-Technologien (XML, XHTML, XQuery, XPath, XSLT) bietet sie einen niedrigschwelligen Einstieg in die Entwicklung von Publikationsplattformen oder kleineren Editionsumgebungen. Nützlich ist eXist-db darüber hinaus auch zur Erkundung umfangreicher Sammlungen von XML-Daten, zur Datentransformation sowie zur Nutzung als reines Datenbank-Backend zur Integration in Webanwendungen, die auf anderen Technologien aufbauen.
Der Kurs behandelt von Grund auf die Installation und Konfiguration einer eXist-Datenbank auf dem eigenen Rechner. Nach einer Übersicht über die grundlegenden Konzepte der Datenbank wird die integrierte Entwicklungsumgebung eXide vorgestellt und anschließend dazu verwendet, erste Datenbankabfragen zu testen. Je nach Vorkenntnissen der TeilnehmerInnen wird eine Wiederholung von XPath sowie eine Einführung in die Abfragesprache XQuery vorangestellt.
Ziel des Workshops ist es, eine kleine Publikationsplattform für eine Briefedition aus bereits vorliegenden TEI-kodierten Daten zu entwickeln. Der Kurs richtet sich an Teilnehmer, die bereits Erfahrung mit XML und (X)HTML haben, bestenfalls bereits Texte oder andere Daten in XML kodiert haben und nun ihre Kenntnisse auf den Bereich der Transformation bzw. Publikation dieser Daten im Web erweitern möchten.
- Kurssprache
- deutsch
- Voraussetzungen/Vorkenntnisse
- Erfahrung mit XML; Erfahrungen mit XPath-Ausdrücken sowie XSLT sind wünschenswert.
- Software
- Keine
- Zielgruppe
- Einsteiger und fortgeschrittene Anfänger
- Kosten
- 20,- Euro
Keynote: Zwischen Sakrileg und Handwerk – Tendenzen der computationellen Analyse schöner Literatur
Fotis Jannidis
Mo, 2. September, 18:00–19:30 Uhr
HNI Foyer
Mining Music Data – Arbeiten mit RISM-Daten
ohannes Kepper
Universität
Paderborn
Musikwissenschaftliches Seminar Detmold/Paderborn
Beethovens
Werkstatt
Axel Ngonga
Laurent Pugin
Do, 5. September, 11:15 Uhr bis Fr, 6. September, 12:45 Uhr
F0.231
Der Kurs bietet eine Einführung in die Techniken des Data Mining anhand der RISM-Daten (https://opac.rism.info/index.php?id=10). Dabei wird u.a. der Umgang mit SPARQL, einer Abfragesprache für RDF-Daten, vermittelt, es soll aber auch um musikspezifische Fragestellungen gehen. Teilnehmer ohne einschlägige Vorkenntnisse sollten den Kurs «Semantic Web/Linked Open Data» besuchen. Kurssprache ist – je nach Anforderungen der Teilnehmer – sowohl deutsch als auch englisch.
The course provides an introduction to data mining techniques using the RISM dataset (https://opac.rism.info/index.php?id=10). Among other things, the use of SPARQL, a query language for RDF data, will be taught, but also music-specific questions will be discussed. Participants without relevant prior knowledge should attend the course «Semantic Web/Linked Open Data». Depending on the requirements of the participants, the course language is both German and English.
- Kurssprache
- Englisch/Deutsch
- Voraussetzungen/Vorkenntnisse
- Keine
- Software
- XML-Editor, Webbrowser
- Zielgruppe
- Anfänger
- Kosten
- 30,– Euro
Postersession
Di, 3. September, 18:00 Uhr bis 19:00 Uhr
HNF Foyer
Die Postersession, an der sich alle TeilnehmerInnen beteiligen können, gibt Gelegenheit, mit einem Poster und max. dreiminütigem Kurzvortrag eigene Ideen und Projekte rund um die Themen «Digitale Musikwissenschaft», «Digitale Musikedition» bzw. «DH im Kontext der Musikwissenschaft» zu präsentieren und zu diskutieren.
Die Poster werden anschließend bis zum Ende der ESS im Foyer hängen, sodass sie auch an den folgenden Tagen als «Werbung» und Diskussionspunkt dienen.
InteressentInnen bitten wir, sich bis zum 1. September anzumelden:
ess@edirom.de
- Kurssprache
- deutsch/englisch
- Voraussetzungen/Vorkenntnisse
- keine
- Zielgruppe
- Einsteiger und Fortgeschrittene
- Kosten
- keine
Programmieren für Kultur- und GeisteswissenschaftlerInnen
Andrew Hankinson,
Bodleian Libraries, University of Oxford
Daniel Röwenstrunk
Universität Paderborn
Musikwissenschaftliches Seminar Detmold/Paderborn
ZenMEM
Mi, 4. September, 09:15 Uhr bis 17:45 Uhr
F1.110
Programmierkenntnisse sind auch für Kultur- und GeisteswissenschaftlerInnen von immer größerer Bedeutung, erlauben sie doch, die Fülle an Forschungsdaten, die nun zu einem Großteil digital vorliegen, automatisiert zu organisieren, zu analysieren und zu prozessieren. Im Rahmen des Kurses sollen basale Methoden des Programmierens vermittelt werden, um einen Einstieg in Programmierkonzepte und -sprachen zu ermöglichen. Es sind explizit keine Vorkenntnisse erforderlich. Der Kurs wird auf deutsch und englisch angeboten.
Programming skills are of increasing importance also to humanities scholars as they allow them to automatically organize, analyze, and process the wealth of research data, most of which are digitally available by now. The course aims at teaching basic methods of programming in order to gain access to programming concepts and languages. There is no prior knowledge required. The course is offered in german and english.
- Kurssprache
- deutsch/englisch
- Voraussetzungen/Vorkenntnisse
- keine
- Software
- Python (aktuelle Version unter https://www.python.org/)
- Zielgruppe
- Anfänger
- Kosten
- 20,- Euro
Quellenbeschreibung mit MEI
Benjamin W. Bohl
Goethe Universität Frankfurt am Main
Institut für Musikwissenschaft
Bernd Alois Zimmermann-Gesamtausgabe
Irmlind Capelle
Musikwissenschaftliches Seminar Detmold/Paderborn
Detmolder Hoftheater
Do, 5. September, 11:15 Uhr bis Fr, 6. September, 12:45 Uhr
F2.221
Jede MEI-Datei verlangt einen sog. Header, in dem u. a. die Quelle der nachfolgenden Musik-Codierung angegeben wird. Dabei kann es sich um sehr unterschiedliche Quellentypen handeln: Es können gedruckte oder handschriftliche Noten sein, aber auch Audio-Dateien oder digitale Vorlagen in anderer Codierung etc.
Darüber hinaus hat sich aber MEI auch als Format für «reine» Quellenbeschreibung etabliert, da MEI als XML-Format – im Gegensatz zu proprietären Datenbanken – sehr gut für den digitalen Austausch und die digitale Vernetzung geeignet ist. Aus diesem Grund wurden bei der letzten Aktualisierung zu MEI 4.0 sehr viele Elemente neu aufgenommen, die den professionellen Ansprüchen von Quellenbeschreibungen entsprechen.
Der Kurs gibt ausgehend von den minimalen Anforderungen einer reinen Quellenangabe, Einblicke in die detaillierte Quellenbeschreibung (unter Berücksichtigung des FRBR-Modells) und die durch MEI 4.0 eingeführten neuen Möglichkeiten
Die Teilnehmer sind ausdrücklich aufgefordert, Materialien aus dem eigenen Arbeitsbereich mitzubringen.
- Kurssprache
- deutsch
- Voraussetzungen/Vorkenntnisse
- möglichst XML Grundkenntnisse, vorzugsweise MEI Kenntnisse
- Software
- Oxygen XML Editor
- Zielgruppe
- Kosten
- 30,- Euro
Semantic Web/Linked Open Data
Stefan Münnich
David Weigl
Institut für musikalische Akustik – Wiener Klangstil
Mo, 2. September, 14:15 Uhr bis Di, 3. September, 17:45 Uhr
F0.225
Linked (Open) Data und das sogenannte Semantic Web (https://www.w3.org/standards/semanticweb/) spielen eine zunehmend wichtigere Rolle sowohl in den digitalen Geisteswissenschaften allgemein als auch in musikwissenschaftlichen/musikeditorischen Zusammenhängen im Speziellen. Darunter fallen u. a. Fragestellungen wie die (weltweite) Bereitstellung, Referenzierbarkeit und Verknüpfung von Forschungsdaten, die (Wieder-)Verwendung von kontrollierten Vokabularen und Ontologien sowie Abfragemöglichkeiten existierender Graphdatenbanken.
Der Workshop ist als Einführung in dieses Themengebiet gedacht und wird neben den grundlegenden Konzepten und Technologien (URI, RDF, OWL, SPARQL, Web Annotations) auch die dahinterliegende Vision eines «Web of Data» (Tim Berners Lee, 2001) thematisieren. Diesen theoretischen Grundlagen werden ausgewählte musikspezifische Anwendungsfälle (z. B. SPARQL-Abfrage der RISM-Datenbank, MELD, TROMPA, DOREMUS, Music Ontology, Metadaten mit FRBR/FRBRoo) und für den praktischen Umgang mit semantischen Technologien nützliche und frei zugängliche Tools zur Seite gestellt.
Der Kurs richtet sich an Anfänger, es sind keine Vorkenntnisse erforderlich. Ein grundsätzliches Verständnis des «klassischen» World Wide Webs ist jedoch von Vorteil.
- Kurssprache
- deutsch
- Voraussetzungen/Vorkenntnisse
- keine
- Zielgruppe
- Einsteiger
- Kosten
- 30,– Euro
Spotlights
Mit diesem Format erhalten Teilnehmerinnen und Teilnehmern der ESS die Gelegenheit, eigene Projekte, Themen, interessante Technologien, Probleme oder Fragestellungen im Rahmen einer 90-minütigen Veranstaltung zur Diskussion zu stellen.
Für den Besuch dieser Veranstaltungen ist keine Anmeldung notwendig. Die Spotlights sind kostenlos für Anfänger und Fortgeschrittene zugänglich.
Di, 3. September, 9:15–10:45 Uhr
Raum: F0.231
Daniel Röwenstrunk
Nationale Forschungsdateninfrastruktur
«Die nationale Forschungsdateninfrastruktur (NFDI) soll die Datenbestände von Wissenschaft und Forschung systematisch erschließen, nachhaltig sichern und zugänglich machen sowie (inter-)national vernetzen. Sie wird in einem aus der Wissenschaft getriebenen Prozess als vernetzte Struktur eigeninitiativ agierender Konsortien aufgebaut werden.»
So lautet die offizielle Erläuterung der DFG. Daniel Röwenstrunk wird den Stand der Vorbereitungen und die Bedeutung für geisteswissenschaftliche Daten kurz erläutern. Anschließend besteht Zeit zu Rückfragen und zur Diskussion.
Do, 5. September, 9:15–10:45 Uhr
Raum: F0.231
Elena Schilke
Webarchiv Software: Theatre Tool und Metadata Editor für MEI und TEI.
Vorgestellt werden zwei Webanwendungen, die im Detmolder Hoftheater-Projekt (www.hoftheater-detmold.de) und im Pasticcio-Projekt (www.pasticcio-project.eu) entwickelt werden. Zum einen handelt es sich um das «Theatre Tool», einem Webarchiv, das für das Hoftheaterprojekt entwickelt wurde, das aber durch leichte Konfigurationen auch in ähnlichen Projekten einsetzbar ist. Für beide Projekte wird der Metadaten Editor entwickelt, der für Personen, Organisationen, Werke und Orte bereits einsetzbar ist.
Es werden jeweils die Tools erläutert und anschließend erprobt und zur Diskussion gestellt. Wer die Tools selbst ausprobieren möchte, sollte aus Zeitgründen die eXist-Datenbank möglichst bereits installiert haben.
Do, 5. September, 9:15–10:45 Uhr
Raum: F0.225
Alan Riedel
Normierung von Instrumentalbesetzungen mit Linked Open Data. Ein Wikibase-basiertes spartenübergreifendes Crowd Sourcing-Projekt
Es geht um ein Framework, auf dessen Grundlage in einem spartenübergreifenden Crowd-Sourcing-Verfahren eine Ontologie von Instrumenten und Instrumentalbesetzungen erschaffen werden kann. Über dieses gemeinsam erstellte interoperable Vokabular, das nach LOD-Grundsätzen aufgebaut werden soll, könnten dann Beispielsweise Objekte (real-existierende Musikinstrumente aus Museumssammlungen) mit bibliographischen Werkdatensätzen oder digitalen Editionen Verknüpft werden. Gleichzeitig würde es als normatives, kontrolliertes Vokabular ein Desiderat für Erschließungstätigkeiten aller Kulturerbesparten ausfüllen, bei dem die gängigen Vokabulare (GND, LCSH) keine adäquaten Darstellungsmöglichkeiten bieten. Als Software für dieses Projekt eignet sich insbesondere Wikibase – die Grundlage von Wikidata. In dieser Software Integriert ist auch ein SPARQL-Endpoint, der auch ganz neue Suchmöglichkeiten in den Beständen von Teilnehmern bieten könnte.
Do, 5. September, 9:15–10:45 Uhr
Raum: F1.110
Nikolaos Beer
Die Reger-Werkausgabe auf dem Weg ins Max-Reger-Portal – Digitale Musikedition mit Edirom im Kontext eines Komponistenportals
Erste digitale Gehversuche im Max-Reger-Institut (MRI) reichen bis in die Mitte der 1980er-Jahre zurück. Die damalige Anschaffung eines Computers ermöglichte nicht nur die vereinfachte Erstellung textbasierter Forschungspublikationen, vielmehr stellte der Einsatz von Datenbankprogrammen und die seit Mitte der 1990er-Jahre forcierte digitale Katalogisierung und Erfassung der Archiv- und Sammlungsbestände sowie externer «Regeriana» eine immense Vereinfachung der Recherche- und Forschungsarbeit dar. Projekte wie das Reger-Werk-Verzeichnis (RWV), das Reger-Briefe-Verzeichnis (RBV) und aktuell die Reger-Werkausgabe (RWA) wären ohne diese grundlegende Vorarbeit in der vorliegenden Tiefe kaum denkbar.
Seit Beginn der Reger-Werkausgabe im Jahr 2008 ist die Reger-Forschung am MRI ein steter Begleiter der Edirom-Community. In dieser Zeit sind 10 Hybrid-Editionsbände mit inzwischen über 100 edierten Werken (Orgelwerke, Lieder und Chorwerke) Max Regers sowie einer umfassenden digitalen Enzyklopädie erschienen. Zwei wesentliche Aspekte bei der Erarbeitung der Editionen sind die umgehende Reintegration in den Gesamtdatenbestand des MRI sowie die unkomplizierte Nachnutzung (soweit rechtlich möglich) in anderen Forschungs- und Publikationskontexten.
Getreu dem Arbeitsauftrag des MRI, Werk und Leben Max Regers einer breiten Öffentlichkeit zugänglich zu machen, wird im MRI parallel zur RWA das online zugängliche Max-Reger-Protal (MRP) aufgebaut. In seiner ersten Ausbaustufe vorwiegend als Publikations- bzw. Vermittlungsportal konzipiert, wird es derzeit um eine umfangreiche Recherchekomponente erweitert, die Zugriff auf die nur vor Ort im MRI einsehbaren digitalen Kataloge ermöglichen wird. In einer Beta-Version, die im Verlauf des Herbstes auf dem MRP zugänglich sein wird, werden dabei der etwa 14.000 Einträge umfassende Briefkatalog sowie der Personen- und Institutionenkatalog einsehbar sein.
Dieses Spotlight soll einen Einblick in den aktuellen Stand der Arbeiten an der Recherchekomponente des MRP geben und aufzeigen, wie eine Zusammenführung unterschiedlichster Forschungsdaten aus der Arbeit im MRI und an der RWA in einem komponistenbezogenen Forschungsportal gestaltet werden kann. Für die RWA wird sich hierbei auch ein neuer Distributionsweg aufzeigen, der die immer stärker zu Tage tretenden Unzulänglichkeiten der DVD-Publikation kompensieren wird können.
Workflows und Tools im Kontext digitaler Editionen
Daniel Röwenstrunk
Universität Paderborn
Musikwissenschaftliches Seminar Detmold/Paderborn
ZenMEM
Do, 5. September, 11:15 Uhr bis Fr, 6. September, 12:45 Uhr
F0.225
Welche Möglichkeiten bieten die Workflows und Werkzeuge, die das Zentrum Musik – Edition – Medien (ZenMEM) für die Erstellung digitaler Musikeditionen bereit hält? Ausgehend von einem Überblick über wissenschaftlich-kritische Musikeditionen in digitaler Form werden die Methoden und Werkzeuge vorgestellt und an einer Beispieledition praktisch erprobt. Dieser Workshop richtet sich insbesondere an künftige und aktuelle Benutzer der Werkzeuge des ZenMEM. Teilnehmer, die sich grundlegend über Workflows und Werkzeuge informieren möchten, sind ebenfalls herzlich willkommen.
- Kurssprache
- deutsch
- Voraussetzungen/Vorkenntnisse
- Keine
- Software
- Browser (Chrome, Firefox, Safari)
- Zielgruppe
- Anfänger
- Kosten
- 30,- Euro